Cloud data platform layered architecture
This is my learning note from the book Designing Cloud Data Platforms written by Danil Zburivsky and Lynda Partner. Support the authors by buying the book from Designing Cloud Data Platforms – Manning Publications
In chapter 1 we introduced a very high-level architecture of a data platform. It had four layers (ingestion, storage, processing, and serving)
In this chapter, we will expand on this data platform architecture and provide more details about specific functional components. Below figure shows a more sophisticated data platform architecture that builds on our simpler version from chapter 1 and expands it into six layers. These layers are as follows:
- In the ingestion layer (1), we’re showing a distinction between batch and streaming ingest.
- In our storage layer (2), we’re introducing the concept of slow and fast storage options.
- In our processing layer (3), we discuss how it will work with batch and streaming data, fast and slow storage. We’ve added a new metadata layer (4) to enhance our processing layer.
- We’ve expanded the serving layer (5) to go beyond a data warehouse to include other data consumers.
- We’ve added an overlay layer (6) for ETL and/or orchestration.
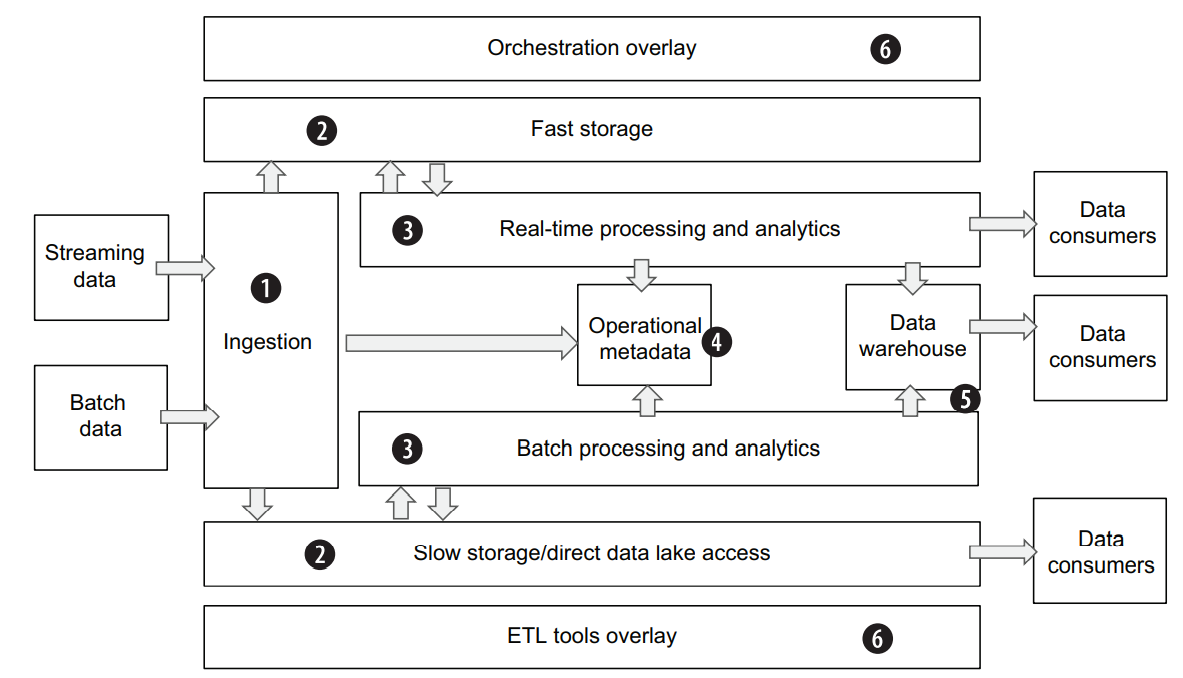
Data ingestion layer
The name of this layer is self-explanatory—it is responsible for connecting to the source systems and bringing data into the data platform.
The data ingestion layer should be able to perform the following tasks:
- Securely connect to a wide variety of data sources—in streaming and/or batch modes.
- Transfer data from the source to the data platform without applying significant changes to the data itself or its format.
- Preserving raw data in the lake is important for cases where data needs to be reprocessed later, without having to reach out to the source again.
- Register statistics and ingestion status in the metadata repository.
For example, it’s important to know how much data has been ingested either in a given batch or within a specific time frame if it’s a streaming data source.
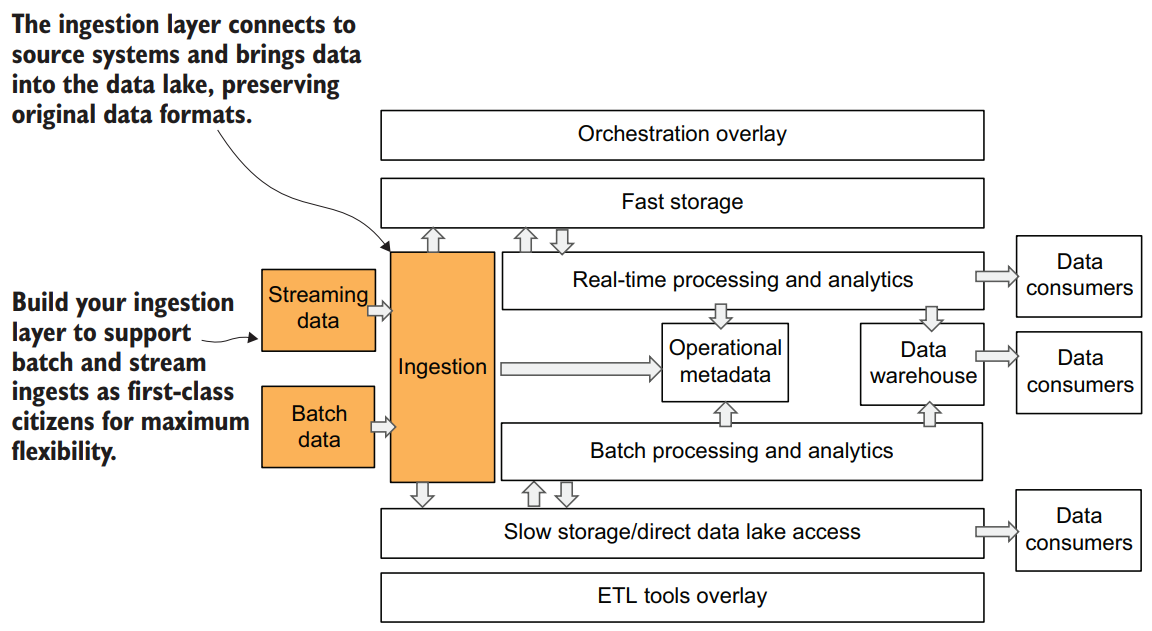
You can see in below figure that our architecture diagram has both batch and streaming ingestion coming into the ingestion layer.
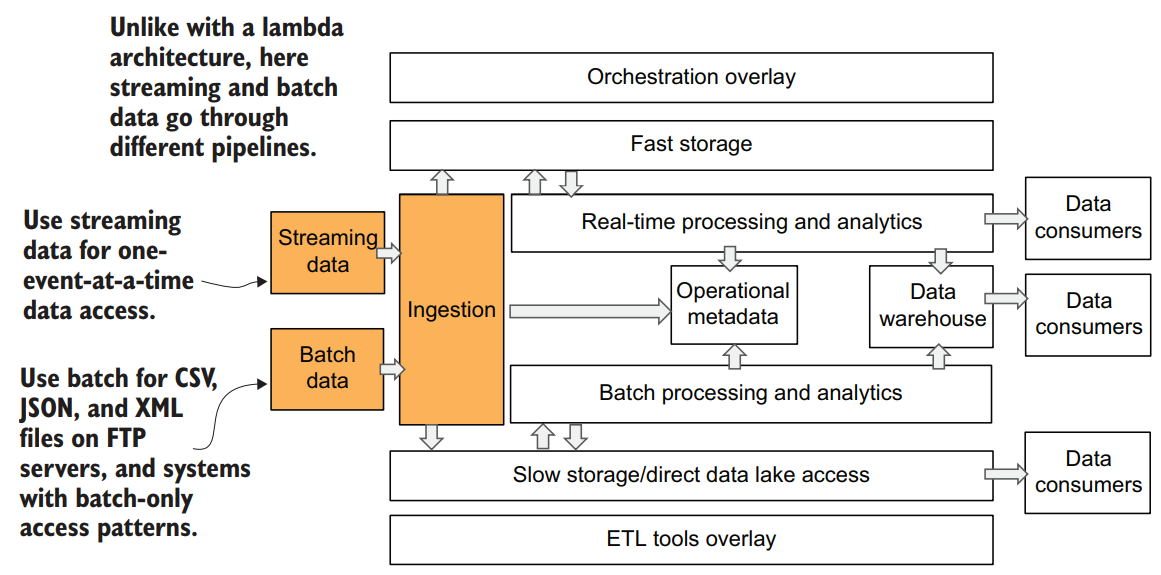
We believe that it’s sound architectural thinking to build your data ingestion layer to support both batch and streaming ingestion as first-class citizens. This means using appropriate tools for different types of data sources. For example, instead of creating a true streaming capability, you could ingest streaming data as a series of small batches, but you will give up the ability to perform real-time analytics in the future. Our design should prevent such technical debt. This way, you will always be able to ingest any data source, no matter where it comes from. And this is one of the most important characteristics of a data platform.
NOTE: We often hear from companies that their data platform must be “realtime,” but we’ve learned that it’s important to unpack what real-time means when it comes to analytics. In our experience, there are often two different interpretations: making data available for analysis as soon as it’s produced at the source (i.e., real-time ingestion) or immediately analyzing and taking action on data that has been ingested in real time (i.e., real-time analytics). Fraud detection and real-time recommendation systems are good examples of real-time analytics. Most of our customers actually don’t need real-time analytics, at least not yet. They simply want to ensure that the data they use to produce insights is up to date, meaning as current as a few minutes or hours ago, even though the report or dashboard may only be looked at periodically. Given that real-time analytics is much more complex than real-time ingestion, it’s often worth exploring user needs in detail to fully understand how to best architect your data platform
Fast and slow storage
Because the data ingestion layer usually doesn’t store any data itself, though it may use transient cache, once data is passed through the ingestion layer, it must be stored reliably. The storage layer in the data platform architecture is responsible for persisting data for long-term consumption. It has two types of storage—fast and slow
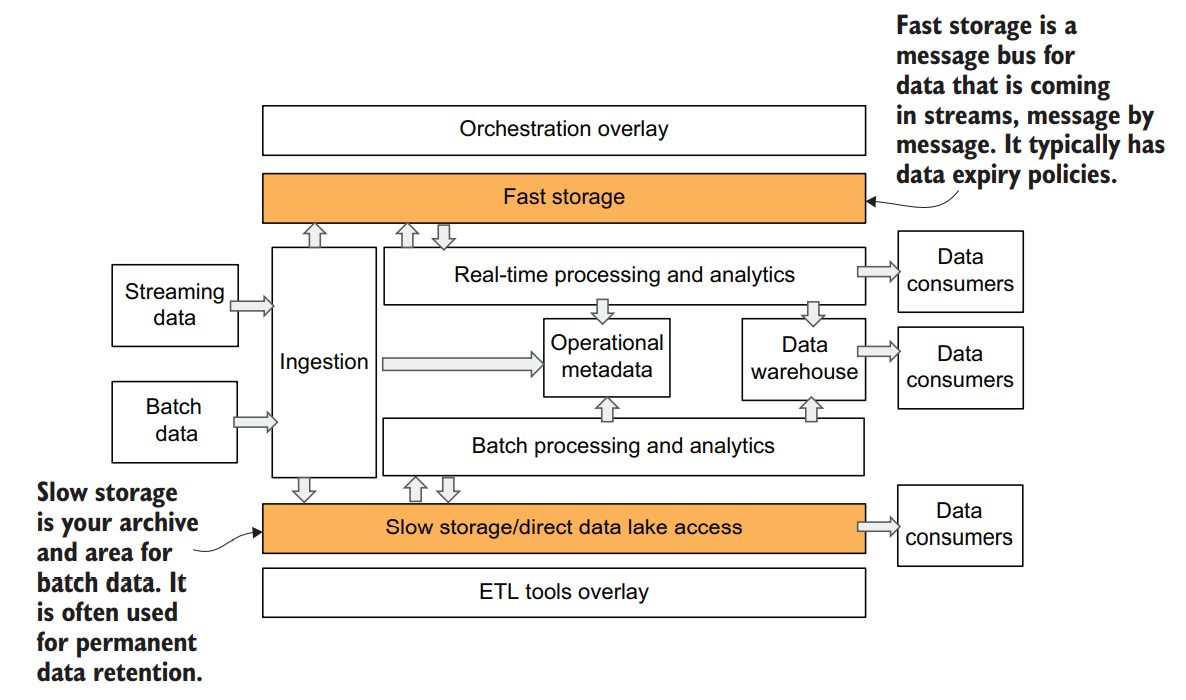
Fast and slow here is not a reference to specific hardware characteristics, such as the difference between HDD and SSD drives, but rather the characteristics of the storage software design and use cases it is targeted for
Slow storage is your main storage for archive and persistent data. This is where data will be stored for days, months, and often years or even decades. In a cloud environment, this type of storage is available as a service from the cloud vendors as an object store that allows you to cost effectively store all kinds of data and support fast reading of large volumes of data.
For streaming use cases, a cloud data platform requires a different type of storage. We call it “fast” storage because it can accommodate low-latency read/write operations on a single message. Most associate storage of this type with Apache Kafka, but there are also services from cloud vendors that have similar characteristics.
Processing layer
This is where all the required business logic is applied and all the data validations and data transformations take place. The processing layer also plays an important role in providing ad hoc access to the data in the data platform
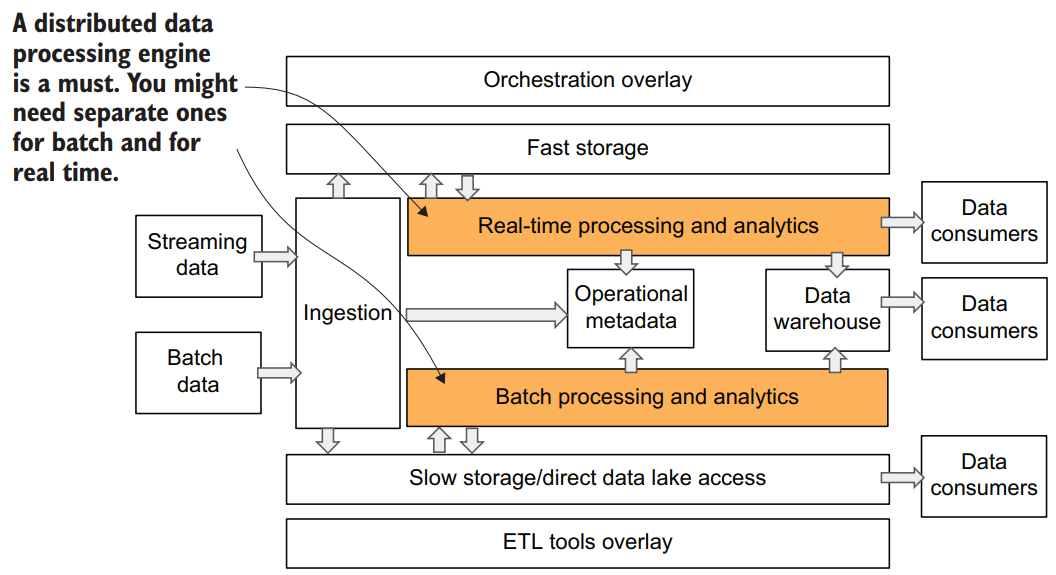
The processing layer should be able to perform the following tasks:
- Read data in batch or streaming modes from storage and apply various types of business logic
- Save data back to storage for data analysts and data scientists to access
- Deliver streaming data outputs to consumers, usually other systems
The processing layer is responsible for reading data from storage, applying some calculations on it, and then saving it back to storage for further consumption. This layer should be able to work with both slow and fast data storage.
Today, there are open source frameworks and cloud services that allow you to process data from both fast and slow storage at the same time. A good example is an open source Apache Beam project and service from Google called Cloud Dataflow, which provides a managed platform-as-a-service execution environment for Apache Beam jobs. Apache Beam supports both batch and real-time processing models within the same framework.
The processing layer should have the following properties:
- Scale beyond a single computer. Data processing framework or cloud service should be able to work efficiently with data sizes ranging from megabytes to terabytes or petabytes.
- Support both batch and real-time streaming models. Sometimes it makes sense to use two different tools for this.
- Support most popular programming languages, such as Python, Java, or Scala.
- Provide a SQL interface. This is more a “nice to have” requirement. A lot of analytics, especially in the ad hoc scenario, is done using SQL. Frameworks that support SQL will significantly increase the productivity of your analysts, data scientists, or data engineers.
Technical metadata layer
Technical metadata, as opposed to business metadata, typically includes but isn’t limited to schema information from the data sources; status of the ingestion; transformation pipelines such as success, failure, error rates, and so on; statistics about ingested and processed data, like row counts; and lineage information for data transformation pipelines.
A data platform metadata store performs the following tasks:
- Stores information about the activity status of different data platform layers
- Provides an interface for layers to fetch, add, and update metadata in the store
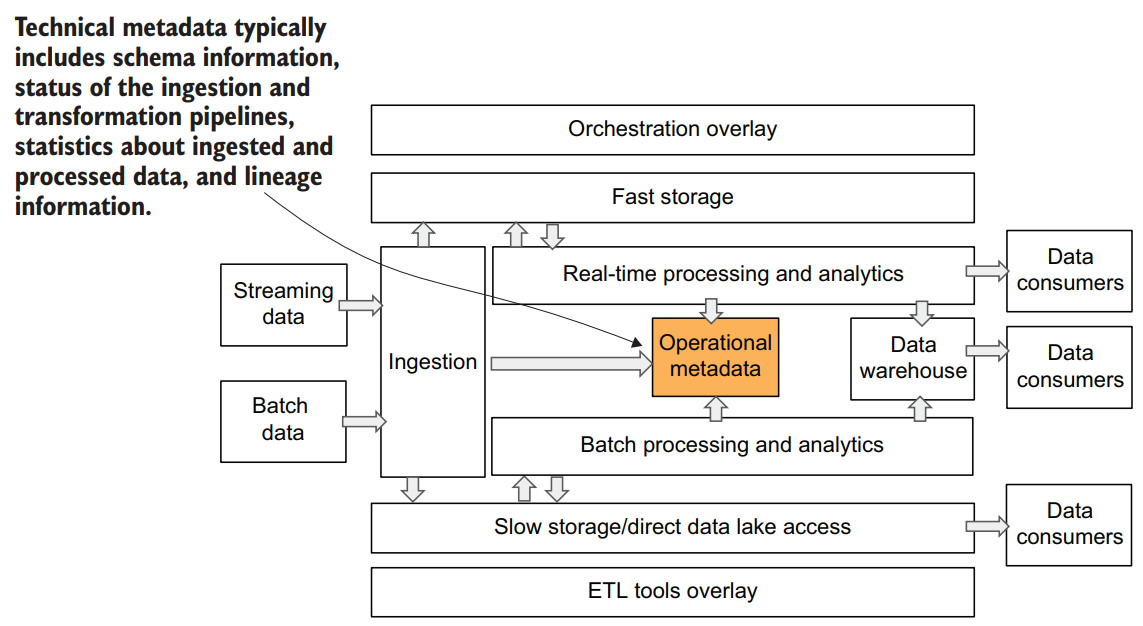
This technical metadata is very important for automation, monitoring and alerting, and developers’ productivity.
Since our data platform design consists of multiple layers that sometimes don’t communicate directly with other layers, we need to have a repository that stores the state of these layers. This allows, for example, the data processing layer to know which data is now available for processing by checking the metadata layer instead of trying to communicate with the ingestion layer directly. This allows us to decouple different layers from each other, reducing the complexities associated with interdependencies.
Another type of metadata that you might be familiar with is business metadata, which is usually represented by a data catalog that stores information about what data actually means from a business perspective; for example, what this specific column in this data source represents. Business metadata is an important component of an overall data strategy because it allows for easier data discovery and communication. Business metadata stores and data catalogs are well represented by multiple third-party products and can be plugged into the layered data platform design as another layer.
Technical metadata management in the data platform is a relatively new topic. There are few existing solutions that can fulfill the tasks described here. For example, a Confluent Schema Registry allows you to store, fetch, and update schema definitions, but it doesn’t allow you to store any other types of metadata. Some metadata layer roles can be performed by various ETL overlay services such as Amazon Glue.
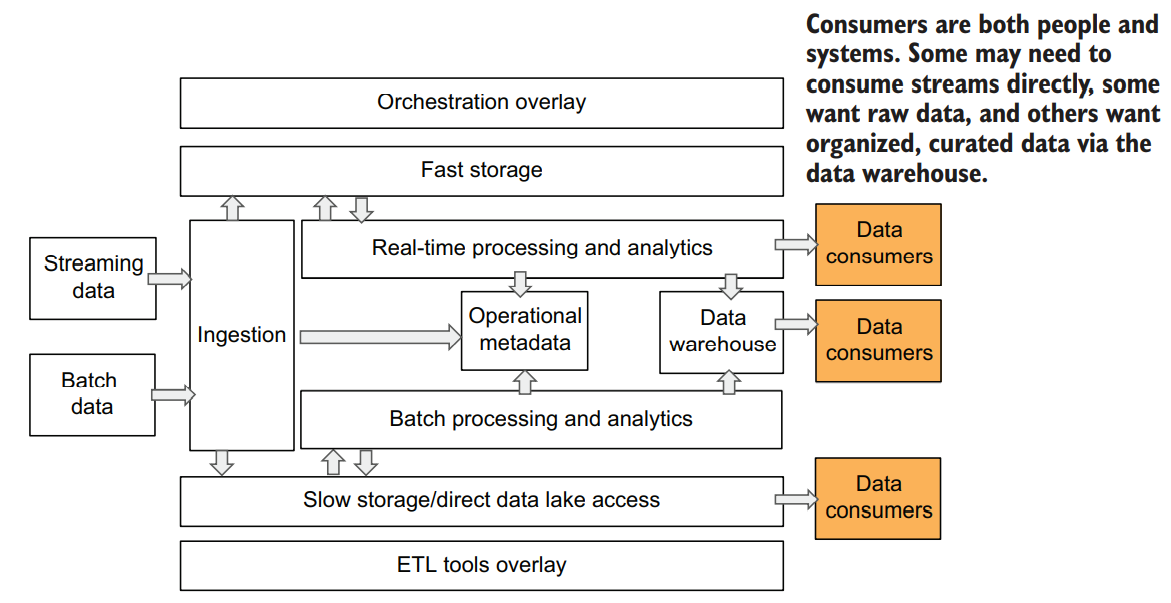
The serving layer and data consumers
The serving layer delivers the output of analytics processing to the various data consumers.
- Serving data to consumers who expect a relational data structure and full SQL support via a data warehouse
- Serving data to consumers who want to access data from storage without going through a data warehouse
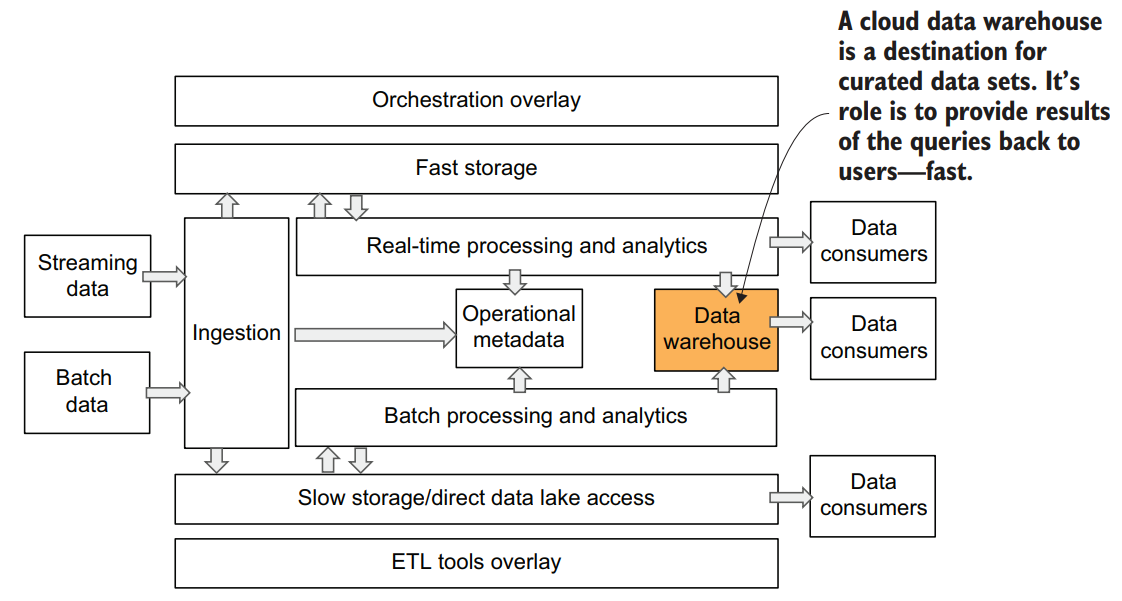
Data warehouses provide a data access point for data consumers that require full SQL support and expect data to be presented in a relational format. Such data consumers may include various existing dashboarding and business intelligence applications, but also data analysts or power business users familiar with SQL
Some data consumers will require direct access to the data in the lake. Usually data science, data exploration, and experimentation use cases fall into this category. Direct access to the data in the lake unlocks the ability to work with the raw, unprocessed data. It also moves experimentation workloads outside of a warehouse to avoid performance impacts.
There are multiple ways to provide direct access to the data in the lake. Some cloud providers, as discussed in the next sections of this chapter, provide a SQL engine that can run queries directly on the files in cloud storage. In other cases, you may use Spark SQL to achieve the same goal. Finally, it’s not uncommon, especially for data science workloads, to just copy required files from the data platform into experimentation environments like notebooks or dedicated data science VMs
Data consumers aren’t always humans. The results of real-time analytics that are being calculated as the data is received a single message at a time are rarely intended to be consumed by a human. Outputs from a real-time analytics pipeline are usually consumed by other applications like marketing activation systems, such as ecommerce recommendation systems that decide which item to recommend to a user while they are shopping, or ad bidding systems where the balance between ad relevance and cost changes in milliseconds.
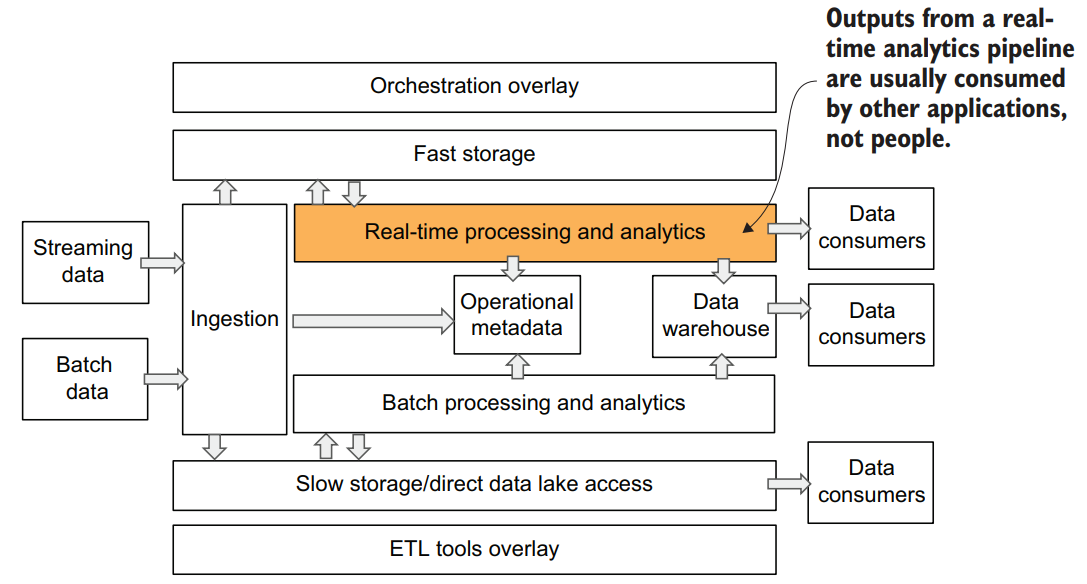
Orchestration and ETL overlay layers
ORCHESTRATION LAYER
In a cloud data platform architecture, the orchestration layer is responsible for the following tasks:
- Coordinate multiple data processing jobs according to a dependency graph (a list of dependencies for each data processing job that includes which sources are required for each job and whether a job depends on other jobs)
- Handle job failures and retries
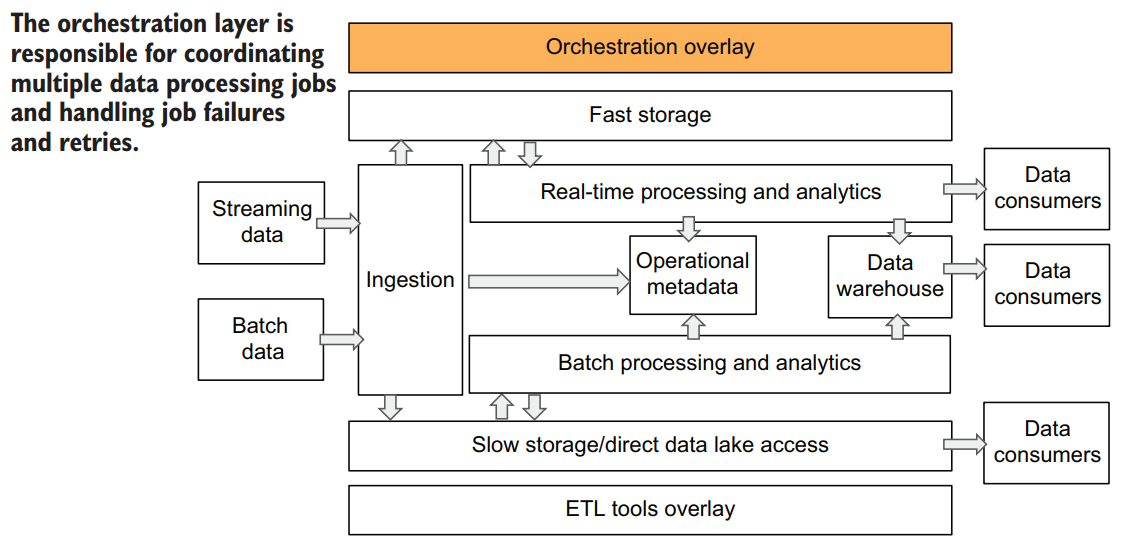
An orchestration layer is responsible for coordinating multiple jobs based on when required input data is available from an external source, or when an upstream dependency is met, such as job 1 needs to complete before job 2 can start. In this case, job implementations remain independent of each other. When they are independent, they can be developed, tested, and changed separately, and the orchestration layer maintains what’s called a dependency graph—a list of dependencies for each data processing job that includes which sources are required for each job and whether a job depends on other jobs. A dependency graph need only be changed when the logical flow of the data is changed, for example, when a new step in processing is introduced. It doesn’t have to be changed when an implementation of a certain step changes.
When it comes to native cloud services, different cloud providers approach the orchestration problem differently. As mentioned, Google adopted Airflow and made it available as a managed service, simplifying the operational aspect of managing the orchestration layer. Amazon and Microsoft include some orchestration features into their ETL tools overlay products.
ETL TOOLS OVERLAY
An ETL tools overlay is a product or a suite of products whose main purpose is to make the implementation and maintenance of cloud data pipelines easier. Usually these tools have a user interface and allow for data pipelines to be developed and deployed with little or no code.
ETL overlay tools are usually responsible for Adding and configuring data ingestion from multiple sources (ingestion layer) Creating data processing pipelines (processing layer) Storing some of the metadata about the pipelines (metadata layer) Coordinating multiple jobs (orchestration layer)
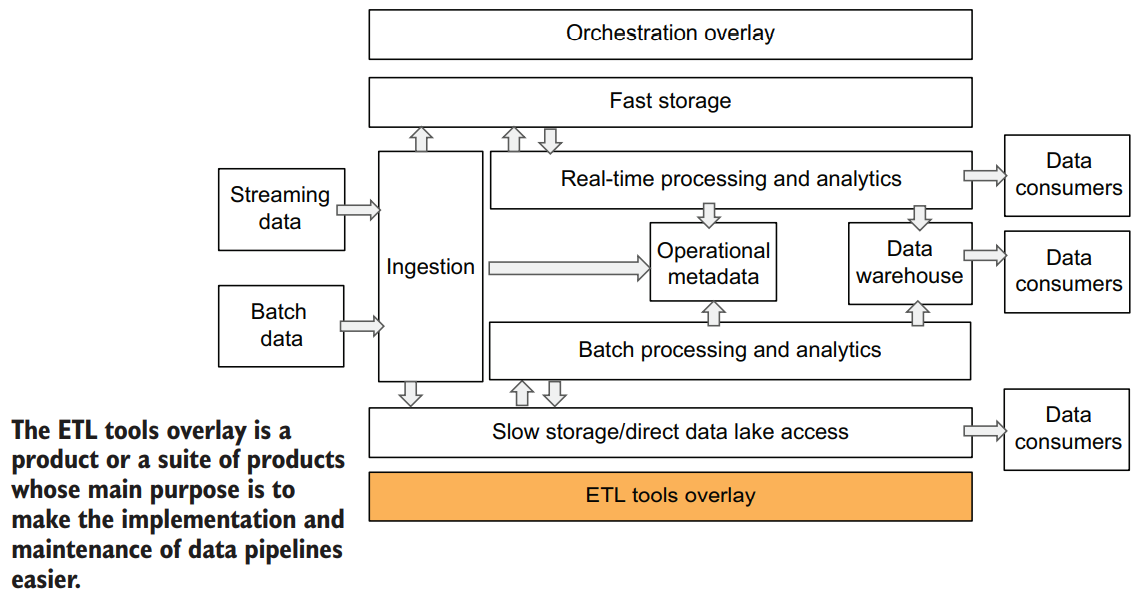
When it comes to existing ETL overlay solutions, there are many available options. Later in this chapter, we will take a look at the cloud services AWS Glue, Azure Data Factory, and Google Cloud Data Fusion.
NOTE Today we are seeing an increasing interest in multicloud solutions, where an organization decides to utilize components across different cloud vendors. Sometimes this is done to reduce the risk of vendor lock-in, but more and more often it is done to utilize best-in-class products that each cloud has to offer. For example, we have seen cases where an organization was performing the bulk of their analytics on AWS but decided to implement their machine learning use cases on Google Cloud. A layered cloud data platform design allows you to not only mix and match products and services within one provider, but also build successful multicloud solutions.
