Mixture of Experts (MoE) is like a teamwork technique in the world of neural networks. Imagine breaking down a big task into smaller parts and having different experts tackle each part. Then, there's a clever judge who decides which expert's advice to follow based on the situation, and all these suggestions are blended together.
Although it was first explained using nerdy neural network stuff, you can use this idea with any type of expert or model. It's a bit like when you combine different flavors to make a tasty dish, and this belongs to the cool group of ensemble learning methods called meta-learning.
So, in this guide, you'll get to know the mixture of experts trick for teaming up models.
Once you're through with this guide, you'll have a handle on:
- How a smart way to work together involves dividing tasks and letting experts handle each part.
- Mixture of experts is a cool method that tries to solve prediction problems by thinking about smaller tasks and expert models.
- This idea of breaking things down and building up connects to decision trees, and the meta-learner concept is kind of like the super-stacker in the ensemble world.
Subtasks and Experts
Let's break it down a bit further: sometimes tasks in the world of prediction can get pretty complex, but the cool thing is, they can often be split into smaller pieces that make more sense.
Imagine you're trying to understand a wiggly line on a graph that looks like the letter "S". Instead of trying to figure out the whole thing at once, you could be smart and chop it into three parts: the top wiggly part, the bottom wiggly part, and the straight line in the middle.
This way of solving problems is kind of like taking things one step at a time, and it's used in all sorts of clever computer techniques for predicting stuff and problem-solving in general.
This approach also forms the basis for creating a special teamwork technique called ensemble learning.
Here's how it works: let's say you're dealing with a tricky puzzle. You can split the puzzle pieces into different groups based on what you already know about the problem. Then, you train a smarty-pants model on each group, so they become experts on their specific part of the puzzle. These experts can then team up and help predict new stuff in the future.
Sometimes these puzzle pieces might overlap, and even experts who know about similar things can lend a hand with predictions that might seem a bit outside their comfort zone.
This ensemble learning is what's behind a fancy method called "mixture of experts."
Mixture of Experts
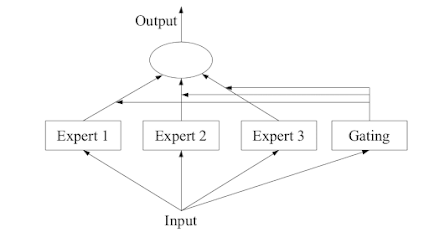
Alright, let's dive into "Mixture of Experts," or you can just call it MoE or ME for short. It's like a team strategy for learning that puts the spotlight on training experts to handle different parts of a problem we're trying to predict.
This approach has four main steps:
- Split the big problem into smaller pieces, like a puzzle.
- Train a super-smart expert for each puzzle piece.
- Bring in a decision-maker, known as a gating model, to choose which expert should take the lead.
- Finally, gather up the experts' advice and the decision-maker's choice to come up with a final prediction.
To give you a visual idea, there's a helpful picture on Page 94 of the 2012 book "Ensemble Methods" that breaks down all these parts and how they fit together.
Expert Models
Now, let's focus on creating our expert models for each of those smaller puzzle pieces.
When the mixture of experts approach first came into play, it was hanging out in the world of artificial neural networks. In this setup, each expert is like a mini-brain that's really good at predicting stuff. If we're dealing with numbers, it can guess a value, and if we're talking categories, it can pick a label.
But here's the cool part: we're not limited to just neural networks as experts. We can swap in any type of model we like. For example, we can use neural networks to play both the role of decision-makers and the experts. When we do this, we call it a "mixture density network."
All these experts get the same set of information (you can think of it as a row of data), and they all take a shot at making a prediction based on that.
Gating Mechanism
Now, here's where the magic comes in. We need a smart buddy to figure out which expert's advice to follow for a given situation. This buddy is called the gating model, or sometimes the gating network, especially if it's a neural network.
This gating network takes in the same information that the expert models got and then decides how much weight each expert's opinion should carry when making a prediction.
Think of it like this: the gating network adjusts its weights on the fly, depending on the information it's given. So, as our mixture of experts learns, it also figures out which parts of the problem each expert is best at tackling.
This gating network is a big deal in this whole process. It's the one that learns to pick the right expert for a specific job and, in turn, helps us make a solid prediction.
You can also look at mixture-of-experts like a fancy way of picking the right classifier for different pieces of the puzzle. Each classifier becomes an expert in a certain part of the information.
When we use neural network models, the gating network and the experts get trained together. This training is like teaching them to work well as a team. In the past, they used something called "expectation maximization" for this. Oh, and the gating network might give each expert a score that looks like a probability, showing how much trust it has in each expert's prediction.
MoE Implementation in Keras
Implementing Mixture of Experts (MoE) models in TensorFlow or Keras involves designing a neural network architecture that combines multiple expert networks with a gating mechanism to determine their contributions. MoE models are typically used for handling complex data distributions and making predictions based on different expert sub-models.
Below is a step-by-step guide on how to implement a basic MoE model using TensorFlow/Keras:
Step 1: Import necessary libraries
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import Dense, Input, Lambda, Layer, Softmax
from tensorflow.keras.models import Model
Step 2: Define the Expert Model
Create a base expert model that will be used as the building block for the mixture. The expert model can be any typical neural network architecture.
def create_expert_model(input_dim, output_dim):
inputs = Input(shape=(input_dim,))
x = Dense(64, activation='relu')(inputs)
x = Dense(32, activation='relu')(x)
outputs = Dense(output_dim, activation='softmax')(x)
model = Model(inputs=inputs, outputs=outputs)
return model
Step 3: Define the Gating Mechanism
Create a gating network that takes the input and outputs the gating coefficients (weights) for each expert. These coefficients determine the contribution of each expert to the final prediction.
def create_gating_network(input_dim, num_experts):
inputs = Input(shape=(input_dim,))
x = Dense(32, activation='relu')(inputs)
x = Dense(num_experts, activation='softmax')(x)
outputs = x
model = Model(inputs=inputs, outputs=outputs)
return model
Step 4: Create the MoE Model
Now, combine the expert models and gating mechanism to create the MoE model. The gating mechanism should be used to compute the weighted sum of expert predictions.
def create_moe_model(input_dim, output_dim, num_experts):
input_layer = Input(shape=(input_dim,))
expert_models = [create_expert_model(input_dim, output_dim) for _ in range(num_experts)]
gating_network = create_gating_network(input_dim, num_experts)
expert_outputs = [expert(input_layer) for expert in expert_models]
gating_coefficients = gating_network(input_layer)
def moe_function(args):
expert_outputs, gating_coefficients = args
return tf.reduce_sum(expert_outputs * tf.expand_dims(gating_coefficients, axis=-1), axis=1)
moe_output = Lambda(moe_function)([expert_outputs, gating_coefficients])
model = Model(inputs=input_layer, outputs=moe_output)
return model
Step 5: Compile and Train the Model
Compile the model with an appropriate loss function and optimizer and train it on your dataset.
# Assuming you have data and labels for training (X_train, y_train)
input_dim = X_train.shape[1]
output_dim = len(np.unique(y_train))
num_experts = 5
moe_model = create_moe_model(input_dim, output_dim, num_experts)
moe_model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
moe_model.fit(X_train, y_train, epochs=10, batch_size=32)


Comments
Post a Comment