
Predicting Nurse Turnover for Highly Imbalanced Data Using the Synthetic Minority Over-Sampling Technique and Machine Learning Algorithms


Abstract
:1. Introduction
2. Literature Review
3. Method
3.1. Research Framework for Nurse Turnover Prediction Model
3.2. Data Collection and Data Preprocessing
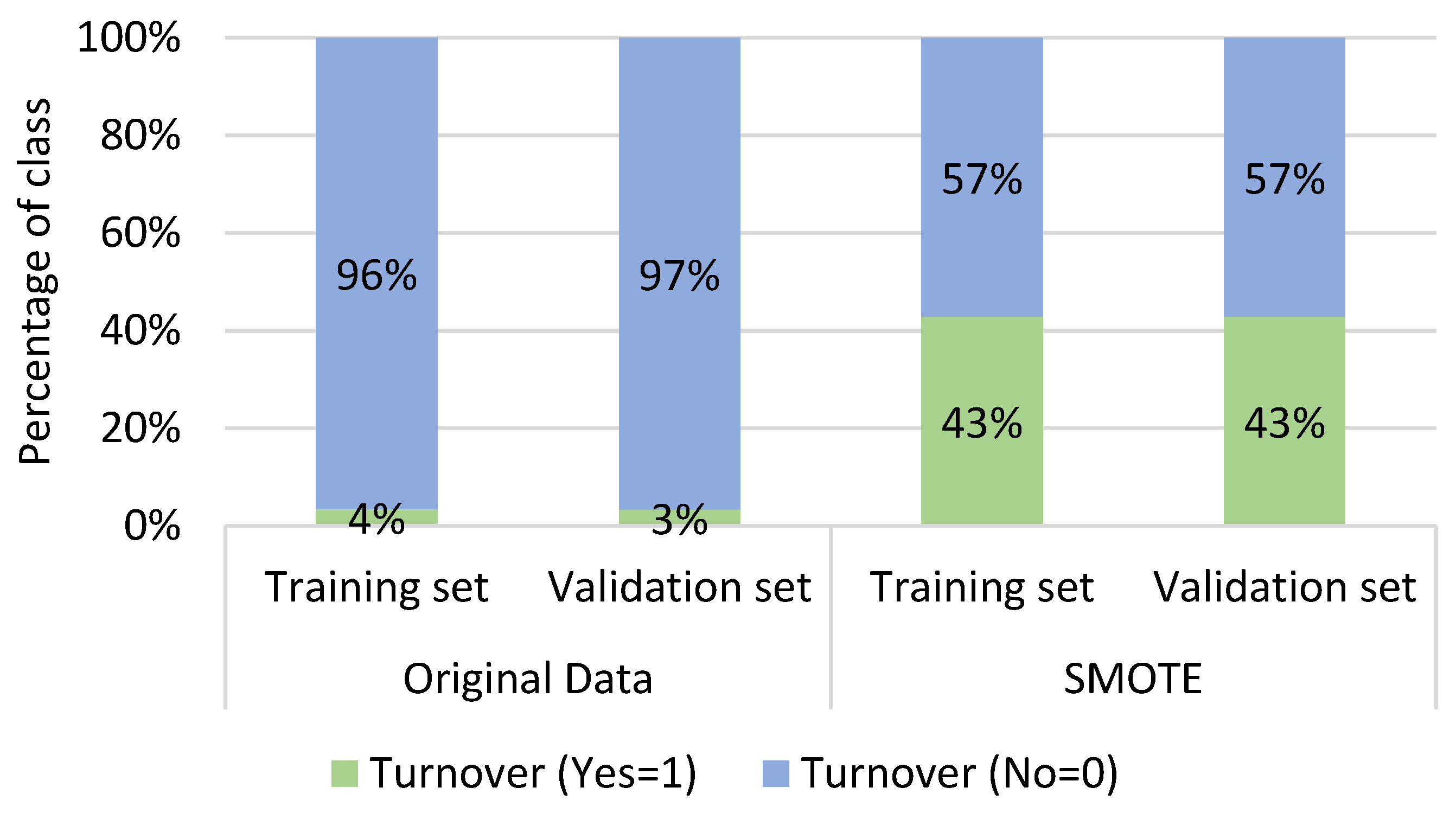
3.3. Sampling Method
3.4. Machine Learning Models
3.4.1. Decision Tree
3.4.2. Random Forest
3.4.3. Logistic Regression
3.4.4. Extreme Gradient Boosting
3.4.5. Performance Metrics
- True Positive (TP): Records of actual “Yes” for turnover are correctly identified as “Yes”.
- False Negative (FN): Records of actual “Yes” for turnover are incorrectly identified as “No”.
- False Positive (FP): Records of actual “No” for turnover are incorrectly identified as “Yes”.
- True Negative (TN): Records of actual “No” for turnover are correctly identified as “No”.
4. Results
4.1. Experiment Setup
4.2. Characteristics of the Participants
4.3. Machine Learning Analysis Results
4.4. Feature Importance of ML Models
4.5. ML Model Performance of Nurse Turnover Prediction
4.6. Optimized Random Forest Analysis Result
5. Conclusions
5.1. Implications of the Study
5.2. Limitations of the Study
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- U.S. Bureau of Labor Statistics. “Healthcare Occupations,” Occupational Outlook Handbook; U.S. Bureau of Labor Statistics: Washington, DC, USA, 2022. [Google Scholar]
- Mirzaei, A.; Moghaddam, H.R.; Soola, A.H. Identifying the predictors of turnover intention based on psychosocial factors of nurses during the COVID-19 outbreak. Nurs. Open 2021, 8, 3469–3476. [Google Scholar] [CrossRef] [PubMed]
- Bracarense, C.F.; Costa, N.D.S.; Raponi, M.B.G.; Goulart, B.F.; Chaves, L.D.P.; de Assis Simões, A.L. Organizational climate and nurses’ turnover intention: A mixed method study. Rev. Bras. Enferm. 2022, 75, e20210792. [Google Scholar] [CrossRef] [PubMed]
- Smokrović, E.; Kizivat, T.; Bajan, A.; Šolić, K.; Gvozdanović, Z.; Farčić, N.; Žvanut, B. A Conceptual Model of Nurses’ Turnover Intention. Int. J. Environ. Res. Public Health 2022, 19, 8205. [Google Scholar] [CrossRef] [PubMed]
- LHayes, L.J.; O’brien-Pallas, L.; Duffield, C.; Shamian, J.; Buchan, J.; Hughes, F.; Laschinger, H.K.S.; North, N.; Stone, P.W. Nurse turnover: A literature review. Int. J. Nurs. Stud. 2006, 43, 237–263. [Google Scholar] [CrossRef]
- Kim, S.K.; Kim, E.J.; Kim, H.K.; Song, S.S.; Park, B.N.; Jo, K.W. Development of a Nurse Turnover Prediction Model in Korea Using Machine Learning. Healthcare 2023, 11, 1583. [Google Scholar] [CrossRef] [PubMed]
- Bae, S.H. Association of Work Schedules with Nurse Turnover: A cross-Sectional National Study. Int. J. Public Health 2023, 68, 160573. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Xu, L.; Cheng, X.; Chao, K.; Zhao, X. Analysis and Prediction of Employee Turnover Characteristics based on Machine Learning. In Proceedings of the ISCIT 2018—18th International Symposium on Communication and Information Technology, Bangkok, Thailand, 26–29 September 2018; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2018; pp. 433–437. [Google Scholar] [CrossRef]
- Moreland, J.J.; Ewoldsen, D.R.; Albert, N.M.; Kosicki, G.M.; Clayton, M.F. Predicting Nurses’ Turnover: The Aversive Effects of Decreased Identity, Poor Interpersonal Communication, and Learned Helplessness. J. Health Commun. 2015, 20, 1155–1165. [Google Scholar] [CrossRef]
- Atef, M.; Elzanfaly, D.S.; Ouf, S. Early Prediction of Employee Turnover Using Machine Learning Algorithms. Int. J. Electr. Comput. Eng. Syst. 2022, 13, 135–144. [Google Scholar] [CrossRef]
- Zhang, H.; Wong, L.P.; Hoe, V.C.W. Bibliometric analyses of turnover intention among nurses: Implication for research and practice in China. Front. Psychol. 2023, 14, 1042133. [Google Scholar] [CrossRef]
- Lazzari, M.; Alvarez, J.M.; Ruggieri, S. Predicting and explaining employee turnover intention. Int. J. Data Sci. Anal. 2022, 14, 279–292. [Google Scholar] [CrossRef]
- Masoud, M.; Jaradat, Y.; Rababa, E.; Manasrah, A. Turnover Prediction using Machine Learning: Empirical Study. Int. J. Adv. Soft Comput. Appl. 2021, 13, 1. [Google Scholar]
- Xu, Y.; Park, Y.S.; Park, J.D. Measuring the response performance of U.S. states against COVID-19 using an integrated dea, cart, and logistic regression approach. Healthcare 2021, 9, 268. [Google Scholar] [CrossRef] [PubMed]
- Wang, P.; Zheng, X.; Li, J.; Zhu, B. Prediction of epidemic trends in COVID-19 with logistic model and machine learning technics. Chaos Solitons Fractals 2020, 139, 110058. [Google Scholar] [CrossRef] [PubMed]
- Adil, M.; Ansari, M.F.; Alahmadi, A.; Wu, J.Z.; Chakrabortty, R.K. Solving the problem of class imbalance in the prediction of hotel cancelations: A hybridized machine learning approach. Processes 2021, 9, 1713. [Google Scholar] [CrossRef]
- Leevy, J.L.; Khoshgoftaar, T.M.; Bauder, R.A.; Seliya, N. A survey on addressing high-class imbalance in big data. J. Big Data 2018, 5, 42. [Google Scholar] [CrossRef]
- Lee, Y.; Kang, J. Related factors of turnover intention among Korean hospital nurses: A systematic review and meta-analysis. Korean J. Adult Nurs. 2018, 30, 1–17. [Google Scholar] [CrossRef]
- Lee, Y.; Kim, J.L.; Kim, S.H.; Chae, J. Effect of an Age-Stratified Working Environment and Hospital Characteristics on Nurse Turnover. Health Insur. Rev. Assess. Serv. Res. 2022, 2, 106–119. [Google Scholar] [CrossRef]
- Cho, S.-H.; Lee, J.Y.; Mark, B.A.; Yun, S.-C. Turnover_of_New_Graduate_Nurse. Prof. Soc. 2012, 44, 63–70. [Google Scholar] [CrossRef]
- Lee, S.K.; Ahn, J.; Shin, J.H.; Lee, J.Y. Application of machine learning methods in nursing home research. Int. J. Environ. Res. Public Health 2020, 17, 6234. [Google Scholar] [CrossRef]
- Ishaq, A.; Sadiq, S.; Umer, M.; Ullah, S.; Mirjalili, S.; Rupapara, V.; Nappi, M. Improving the Prediction of Heart Failure Patients’ Survival Using SMOTE and Effective Data Mining Techniques. IEEE Access 2021, 9, 39707–39716. [Google Scholar] [CrossRef]
- HRSA. National Sample Survey of Registered Nurses (NSSRN). Available online: https://bhw.hrsa.gov/data-research/access-data-tools/national-sample-survey-registered-nurses (accessed on 4 October 2023).
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Zhao, Z.; Bai, T. Financial Fraud Detection and Prediction in Listed Companies Using SMOTE and Machine Learning Algorithms. Entropy 2022, 24, 1157. [Google Scholar] [CrossRef] [PubMed]
- Elhazmi, A.; Al-Omari, A.; Sallam, H.; Mufti, H.N.; Rabie, A.A.; Alshahrani, M.; Mady, A.; Alghamdi, A.; Altalaq, A.; Azzam, M.H.; et al. Machine learning decision tree algorithm role for predicting mortality in critically ill adult COVID-19 patients admitted to the ICU. J. Infect. Public Health 2022, 15, 826–834. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z.; Shen, D.; Nie, T.; Kou, Y. A hybrid sampling algorithm combining M-SMOTE and ENN based on Random forest for medical imbalanced data. J. Biomed. Inform. 2020, 107, 103465. [Google Scholar] [CrossRef] [PubMed]
- Dreiseitl, S.; Ohno-Machado, L. Logistic regression and artificial neural network classification models: A methodology review. J. Biomed. Inform. 2002, 35, 352–359. [Google Scholar] [CrossRef] [PubMed]
- Chumachenko, D.; Meniailov, I.; Bazilevych, K.; Chumachenko, T.; Yakovlev, S. Investigation of Statistical Machine Learning Models for COVID-19 Epidemic Process Simulation: Random Forest, K-Nearest Neighbors, Gradient Boosting. Computation 2022, 10, 86. [Google Scholar] [CrossRef]
- Labrague, L.J.; de los Santos, J.A.A. Fear of COVID-19, psychological distress, work satisfaction and turnover intention among frontline nurses. J. Nurs. Manag. 2021, 29, 395–403. [Google Scholar] [CrossRef]
- Rosadi, D.; Arisanty, D.; Andriyani, W.; Peiris, S.; Agustina, D.; Dowe, D.; Fang, Z. Improving Machine Learning Prediction of Peatlands Fire Occurrence for Unbalanced Data Using SMOTE Approach. In Proceedings of the 2021 International Conference on Data Science, Artificial Intelligence, and Business Analytics, DATABIA 2021—Proceedings, Medan, Indonesia, 11–12 November 2021; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2021; pp. 160–163. [Google Scholar] [CrossRef]
- An, M.; Heo, S.; Hwang, Y.Y.; Kim, J.S.; Lee, Y. Factors Affecting Turnover Intention among New Graduate Nurses: Focusing on Job Stress and Sleep Disturbance. Healthcare 2022, 10, 1122. [Google Scholar] [CrossRef]
- Gao, X.; Wen, J.; Zhang, C. An Improved Random Forest Algorithm for Predicting Employee Turnover. Math. Probl. Eng. 2019, 2019, 4140707. [Google Scholar] [CrossRef]
- Bjarnadottir, R.I.; Herzig, C.T.A.; Travers, J.L.; Castle, N.G.; Stone, P.W. Implementation of Electronic Health Records in US Nursing Homes. CIN Comput. Inform. Nurs. 2017, 35, 417–424. [Google Scholar] [CrossRef]
- Melnick, E.R.; West, C.P.; Nath, B.; Cipriano, P.F.; Peterson, C.; Satele, D.V.; Shanafelt, T.; Dyrbye, L.N. The association between perceived electronic health record usability and professional burnout among US nurses. J. Am. Med Inform. Assoc. 2021, 28, 1632–1641. [Google Scholar] [CrossRef]
- Back, C.Y.; Hyun, D.S.; Jeung, D.Y.; Chang, S.J. Mediating Effects of Burnout in the Association Between Emotional Labor and Turnover Intention in Korean Clinical Nurses. Saf. Health Work 2020, 11, 88–96. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Data Type | Description |
|---|---|---|
| Turnover (Dependent Variable) | Categorical | Outcome feature: showing whether the nurse left the primary nursing position (1: Yes, 0: No) |
| Certificate | Categorical | Type of active certification (three-factor levels) NP: Nurse Practitioner, RN: Registered Nurse, Other: Combined variable (Clinical Nurse, Nurse Midwife, Nurse Anesthetist) |
| Region | Categorical | Location of primary nursing position-census division (four-factor levels: West, Midwest, South, and North) |
| Job_Satisfaction | Categorical | Levels of job satisfaction in primary nursing position (Satisfied vs. Dissatisfied) |
| Race | Categorical | Race (White vs. other race (Black or African American, Asian, American Indian or Alaska Native, Native Hawaiian or Other Pacific Islander, Other race)) |
| Sex | Categorical | Sex (Male vs. Female) |
| Marital_Status | Categorical | Marital Status (Single vs. Married): widow, divorced, and separated is considered as Single |
| Veteran | Categorical | Veteran Status (Served vs. Never served): active duty for training and now or past active duty is considered as Served |
| Household_Income | Categorical | Pre-tax annual household income (three-factor levels): $75,000 or less, between $75,000 and $15,000, and more than $150,000 |
| Degree | Categorical | Type of nursing degree: three-factor levels (AND: associate degree, BSN: Bachelor’s degree, MSN: Master’s degree, PhD/DNP/DN: Doctorate) |
| Dependent_6years | Categorical | A binary value indicating whether the nurse lives at home with a dependent who is less than 6 years old (Yes vs. No) |
| EHR_EMR | Categorical | Usability of Electronic Health Record (HER) or Electronic Medical Record (EMR) system (Yes vs. No) |
| Employment_Type | Categorical | Primary nursing position employment situation (Employed by the organization vs. other (employment agency as a traveling nurse, not as a travel nurse, and self-employed or working as needed)) |
| Job_Type | Categorical | Full-time vs. Part-time work |
| Employment_Setting | Categorical | Type of work setting (three-factor levels: Hospital, Clinic/Ambulatory, and Inpatient + other work setting) |
| Practice | Categorical | Ability to practice to the extent of knowledge/education/training (Yes vs. No) |
| Working_Hour | Categorical | Number of hours worked in a typical week (Standard vs. Overtime); working hours greater than 40 is regarded as overtime. |
| Individual_Income | Numerical | Pre-tax annual earnings from primary nursing position ($) |
| Age | Numerical | Age of nurse |
| Confusion Matrix | True Class | ||
|---|---|---|---|
| Positive (Turnorver = Yes) | Negative (Turnorver = No) | ||
| Predicted class | Positive (Turnorver = Yes) | TP (True Positive) | FP (False Positive) |
| Negative (Turnorver = No) | FN (False Negative) | TN (True Negative) | |
| Original Data | SMOTE | |||||||
|---|---|---|---|---|---|---|---|---|
| Characteristic | Turnover | Turnover | Turnover | Turnover | ||||
| Yes (N = 4728), 11% | No (N = 39,209), 89% | Yes (N = 11,349), 43% | No (N = 15,132), 57% | |||||
| Categorical Variables | Count | Percentage | Count | Percentage | Count | Percentage | Count | Percentage |
| Certificate | ||||||||
| Other | 443 | 9.37% | 2748 | 7.01% | 1699 | 19.57% | 1064 | 4.15% |
| NP | 2173 | 45.96% | 19,382 | 49.43% | 4870 | 56.10% | 7483 | 29.20% |
| RN | 2112 | 44.67% | 17,079 | 43.56% | 2112 | 24.33% | 17,079 | 66.65% |
| Region | ||||||||
| Midwest | 1059 | 22.40% | 8950 | 22.83% | 2418 | 21.31% | 3437 | 22.71% |
| North | 893 | 18.89% | 7227 | 18.43% | 2548 | 22.45% | 2706 | 17.88% |
| South | 1574 | 33.29% | 13,084 | 33.37% | 3601 | 31.73% | 5085 | 33.60% |
| West | 1202 | 25.42% | 9948 | 25.37% | 2782 | 24.51% | 3904 | 25.80% |
| Job_Satisfaction | ||||||||
| Dissatisfied | 462 | 9.77% | 3867 | 9.86% | 2623 | 23.11% | 1458 | 9.64% |
| Satisfied | 4266 | 90.23% | 35,342 | 90.14% | 8726 | 76.89% | 13,674 | 90.36% |
| Race | ||||||||
| Other Race | 638 | 13.49% | 5686 | 14.50% | 2894 | 25.50% | 2185 | 14.44% |
| White | 4090 | 86.51% | 33,523 | 85.50% | 8455 | 74.50% | 12,947 | 85.56% |
| Sex | ||||||||
| Female | 4307 | 91.10% | 35,847 | 91.43% | 9128 | 80.43% | 13,862 | 91.61% |
| Male | 421 | 8.90% | 3362 | 8.57% | 2221 | 19.57% | 1270 | 8.39% |
| Marital Status | ||||||||
| Married | 3548 | 75.04% | 29,490 | 75.21% | 7514 | 66.21% | 11,369 | 75.13% |
| Single | 1180 | 24.96% | 9719 | 24.79% | 3835 | 33.79% | 3763 | 24.87% |
| Veteran | ||||||||
| Never Served | 4443 | 93.97% | 36,919 | 94.16% | 9599 | 84.58% | 14,188 | 93.76% |
| Served | 285 | 6.03% | 2290 | 5.84% | 1750 | 15.42% | 944 | 6.24% |
| Household_Income | ||||||||
| Less than $75,000 | 1016 | 21.49% | 8418 | 21.47% | 2586 | 22.79% | 3174 | 20.98% |
| $75,001 TO $150,000 | 2055 | 43.46% | 17,369 | 44.30% | 5090 | 44.85% | 6706 | 44.32% |
| More than $150,001 | 1657 | 35.05% | 13,422 | 34.23% | 3673 | 32.36% | 5252 | 34.71% |
| Degree | ||||||||
| ADN | 773 | 16.35% | 5891 | 15.02% | 2240 | 19.74% | 2215 | 14.64% |
| BSN | 956 | 20.22% | 9395 | 23.96% | 2275 | 20.05% | 3623 | 23.94% |
| MSN | 2404 | 50.85% | 20,308 | 51.79% | 5025 | 44.28% | 7873 | 52.03% |
| PHD/DNP/DN | 595 | 12.58% | 3615 | 9.22% | 1809 | 15.94% | 1421 | 9.39% |
| Dependant < 6 years | ||||||||
| No | 3895 | 82.38% | 32,248 | 82.25% | 8970 | 79.04% | 12,480 | 82.47% |
| Yes | 833 | 17.62% | 6961 | 17.75% | 2379 | 20.96% | 2652 | 17.53% |
| EHR_EMR Usability | ||||||||
| No | 488 | 10.32% | 4595 | 11.72% | 2652 | 23.37% | 1774 | 11.72% |
| Yes | 4240 | 89.68% | 34,614 | 88.28% | 8697 | 76.63% | 13,358 | 88.28% |
| Employment_Type | ||||||||
| Employed by Organization | 4448 | 94.08% | 36,540 | 93.19% | 9259 | 81.58% | 14,123 | 93.33% |
| Other | 280 | 5.92% | 2669 | 6.81% | 2090 | 18.42% | 1009 | 6.67% |
| Job_Type | ||||||||
| Full Time | 3764 | 79.61% | 30,964 | 78.97% | 8106 | 71.42% | 11,974 | 79.13% |
| Part Time | 964 | 20.39% | 8245 | 21.03% | 3243 | 28.58% | 3158 | 20.87% |
| Employment_Setting | ||||||||
| Clinical/Ambulatory | 1608 | 34.01% | 13,110 | 33.44% | 3556 | 31.33% | 5022 | 33.19% |
| Hospital | 2058 | 43.53% | 17,551 | 44.76% | 4096 | 36.09% | 6858 | 45.32% |
| Inpatient/Other | 1062 | 22.46% | 8548 | 21.80% | 3697 | 32.58% | 3252 | 21.49% |
| Practice | ||||||||
| No | 1003 | 21.21% | 8512 | 21.71% | 4268 | 37.61% | 3240 | 21.71% |
| Yes | 3725 | 78.79% | 30,697 | 78.29% | 7081 | 62.39% | 11,892 | 78.29% |
| Working Hour | ||||||||
| Standard | 3197 | 67.62% | 27,153 | 69.25% | 7443 | 65.58% | 10,552 | 69.73% |
| Overtime | 1531 | 32.38% | 12,056 | 30.75% | 3906 | 34.42% | 4580 | 30.27% |
| Numerical Variables | Average | Std.dev | Average | Std.dev | Average | Std.dev | Average | Std.dev |
| Age | 55 | 11 | 48 | 12 | 50 | 11 | 49 | 12 |
| Individual Income | 70,285 | 41,404 | 85,444 | 37,157 | 80,471 | 41,404 | 84,069 | 37,157 |
| Independent Variables | Odds Ratio | 95% CI | p-Value |
|---|---|---|---|
| Certificate (ref: NP) | |||
| Other | 1.592 | (1.42,1.78) | *** |
| RN | 1.032 | (0.96,1.11) | |
| Region (ref: Midwest) | |||
| North | 1.037 | (0.95,1.14) | |
| South | 0.837 | (0.77,0.91) | *** |
| West | 0.873 | (0.80,0.95) | ** |
| EHR/EMR Usability (ref: No) | |||
| Yes | 0.567 | (0.52,0.62) | *** |
| Employment Type (ref: Employed by Organization) | |||
| Other | 2.525 | (2.29,2.78) | *** |
| Job Type (ref: Full time) | |||
| Part Time | 1.446 | (1.34,1.56) | *** |
| Employment Setting (ref: Clinical/Ambulatory) | |||
| Hospital | 0.881 | (0.82,0.95) | *** |
| Inpatient/Other | 1.248 | (1.15,1.35) | *** |
| Working Hour (ref: Overtime) | |||
| Standard | 0.732 | (0.69,0.78) | *** |
| Job Satisfaction (ref: Dissatisfied) | |||
| Satisfied | 0.469 | (0.43,0.51) | *** |
| Job Practice (ref: No) | |||
| Yes | 0.577 | (0.54,0.62) | *** |
| Race (ref: Other race) | |||
| White | 0.538 | (0.50,0.58) | *** |
| Sex (ref: Female) | |||
| Male | 2.111 | (1.93,2.31) | *** |
| Marital Status (ref: Married) | |||
| Single | 1.529 | (1.43,1.64) | *** |
| Veteran Status (ref: Never served) | |||
| Served | 2.154 | (1.94,2.39) | *** |
| Household Income (ref: $75,001 to $150,000) | |||
| $75,000 or less | 1.048 | (0.96,1.14) | |
| More than $150,000 | 1.092 | (1.02,1.17) | * |
| Degree (ref: ADN) | |||
| BSN | 0.726 | (0.66,0.80) | *** |
| MSN | 0.730 | (0.66,0.80) | *** |
| PHD/DNP/DN | 1.121 | (1.00,1.26) | |
| Dependent less than 6 years old (ref: No) | |||
| Yes | 1.357 | (1.25,1.47) | *** |
| Individual Income | 0.999 | (1.00,1.00) | |
| Age | 0.998 | (0.99,1.01) |
| SMOTE_RF | SMOTE_XGB | SMOTE_DT | |
|---|---|---|---|
| SMOTE_RF | 1 | ||
| SMOTE_XGB | 0.683893 | 1 | |
| SMOTE_DT | 0.683749 | 0.861878 | 1 |
| SMOTE_DT | True class | ||
| Positive | Negative | ||
| Predicted class | Positive | 2623 (49.5%) | 745 (14.1%) |
| Negative | 403 (7.6%) | 1524 (28.8%) | |
| SMOTE_XGB | True class | ||
| Positive | Negative | ||
| Predicted class | Positive | 2749 (51.0%) | 277 (6.1%) |
| Negative | 592 (11.2%) | 1677 (31.7%) | |
| SMOTE_RF | True class | ||
| Positive | Negative | ||
| Predicted class | Positive | 2714 (51.3%) | 561 (10.6%) |
| Negative | 312 (5.9%) | 1708 (32.3%) | |
| SMOTE_LR | True class | ||
| Positive | Negative | ||
| Predicted class | Positive | 2450 (46.3%) | 1039 (19.6%) |
| Negative | 576 (10.9%) | 1230 (23.2%) | |
| Criterion | SMOTE_LR | SMOTE_RF | SMOTE_DT | SMOTE_XGB |
|---|---|---|---|---|
| Accuracy | 69.40% | 74.39% | 69.90% | 73.88% |
| Recall (sensitivity) | 71.47% | 82.12% | 56.59% | 83.77% |
| Precision | 54.21% | 60.33% | 83.77% | 62.28% |
| F1-score | 61.65% | 69.56% | 67.55% | 71.45% |
| Auc | 69.50% | 77.67% | 73.97% | 76.43% |
| Criterion | SMOTE_LR | SMOTE_RF | SMOTE_DT | SMOTE_XGB |
|---|---|---|---|---|
| Accuracy | 70.39% | 82.21% | 74.84% | 82.19% |
| Recall (sensitivity) | 80.91% | 90.52% | 55.09% | 81.12% |
| Precision | 70.13% | 82.36% | 72.70% | 89.72% |
| F1-score | 75.05% | 88.40% | 62.62% | 85.20% |
| Auc | 73.24% | 80.82% | 76.29% | 80.93% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Park, Y.; Park, J.D.; Sun, B. Predicting Nurse Turnover for Highly Imbalanced Data Using the Synthetic Minority Over-Sampling Technique and Machine Learning Algorithms. Healthcare 2023, 11, 3173. https://doi.org/10.3390/healthcare11243173
Xu Y, Park Y, Park JD, Sun B. Predicting Nurse Turnover for Highly Imbalanced Data Using the Synthetic Minority Over-Sampling Technique and Machine Learning Algorithms. Healthcare. 2023; 11(24):3173. https://doi.org/10.3390/healthcare11243173
Chicago/Turabian StyleXu, Yuan, Yongshin Park, Ju Dong Park, and Bora Sun. 2023. "Predicting Nurse Turnover for Highly Imbalanced Data Using the Synthetic Minority Over-Sampling Technique and Machine Learning Algorithms" Healthcare 11, no. 24: 3173. https://doi.org/10.3390/healthcare11243173