Vibe-Eval: A new open and hard evaluation suite for measuring progress of multimodal language models
Evals are notoriously difficult to get right despite being a critical component and requisite of building great models. At Reka, we believe that investing in solid evals is paramount, high impact, work that can steadily move the field forward. Therefore, we’re glad to be releasing a small part of our internal evaluation suite to the community.
Vibe-Eval is comprised of 269 ultra high quality image-text prompts and their ground truth responses. The quality of prompts and responses has been extensively checked multiple times by our team. Moreover, Vibe-Eval was designed to be difficult, challenging even to the current frontier models, and to induce greater separability among frontier-class models. On 50% of the hard set, all frontier models fail to arrive at a perfect answer leaving a lot of headroom for progress. Check out our paper / technical report here.

Coming up with a diverse set of difficult prompts is a challenging endeavor. It’s also something that cannot be easily explained to typical annotators, since they are not calibrated to the state-of-the-art in multimodal reasoning. To this end, our prompts are created by ourselves (actual AI experts) who have a strong familiarity with the performance of frontier models. Notably, our construction of hard prompts is partially guided by the inability of Reka Core (and some other frontier models) to perform the task.
Vibe-Eval is an evaluation setup for multimodal chat models. While MMMU has been a pretty solid standard for evaluating multimodal models, it is still fundamentally a multiple choice benchmark. To this end, there hasn’t been any well established benchmark yet in the community for multimodal chat models. Meanwhile, despite chatbot arenas being popular and trendy, we think that small, controlled and consistent experiments focusing on capabilities could be complementary.
In our paper, we discuss challenges and trade-offs between human and model-based automatic evaluation and propose a lightweight automatic evaluation protocol based on Reka Core. While we show that Reka Core evaluator strongly correlates with human judgement, we think that human judgements could be complementary and plan to periodically run formal human evaluations on public models that do well on this benchmark. As for lightweight evaluations, we make the Reka Core API free of charge for this purpose. Check out the evaluation code and data at the reka-vibe-eval repo on github.
Some of our findings and research insights:
Hard prompts are difficult to create. It is non-trivial to come up with a benchmark sufficiently hard yet not impossibly difficult for multimodal language models. This is a task that is not easy for external annotators.
Hard prompts are difficult to evaluate. We find that normal prompts have lower human rater variance as compared to hard prompts. We postulate that this is due to ambiguity or lack of context/knowledge to assign partial credit. Models could also fail in very drastically different ways in the face of hard prompts. Hence, there could also be a lot of ambiguity on how to deal with model failures.
Inverse scaling occurs quite a bit, anecdotally. When designing hard prompts, we find that there are a noticeable number of hard prompts where larger frontier models (opus, gpt4v, gemini) fail spectacularly but are solved by smaller models (Reka edge 7b or Idefics-2 8B). We postulate that inverse scaling occurs slightly more than in pure-text setups and is an interesting avenue for future research.
Evaluation Results
We benchmark representative multimodal language models on both human evaluation and vibe-eval’s automatic model based evaluation. We report Human Preference (ELO), Vibe-Eval score and alignment between relative rankings below.
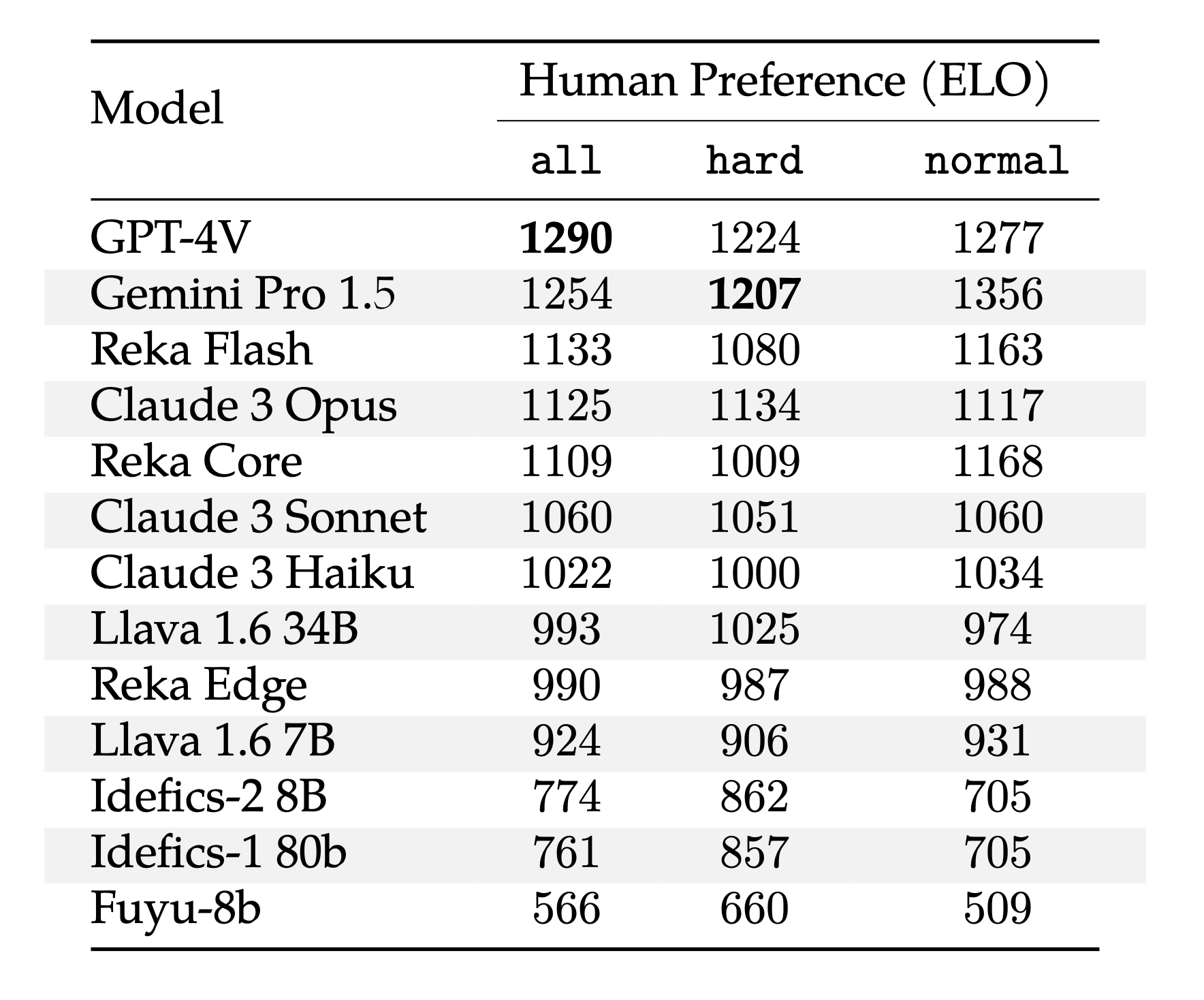
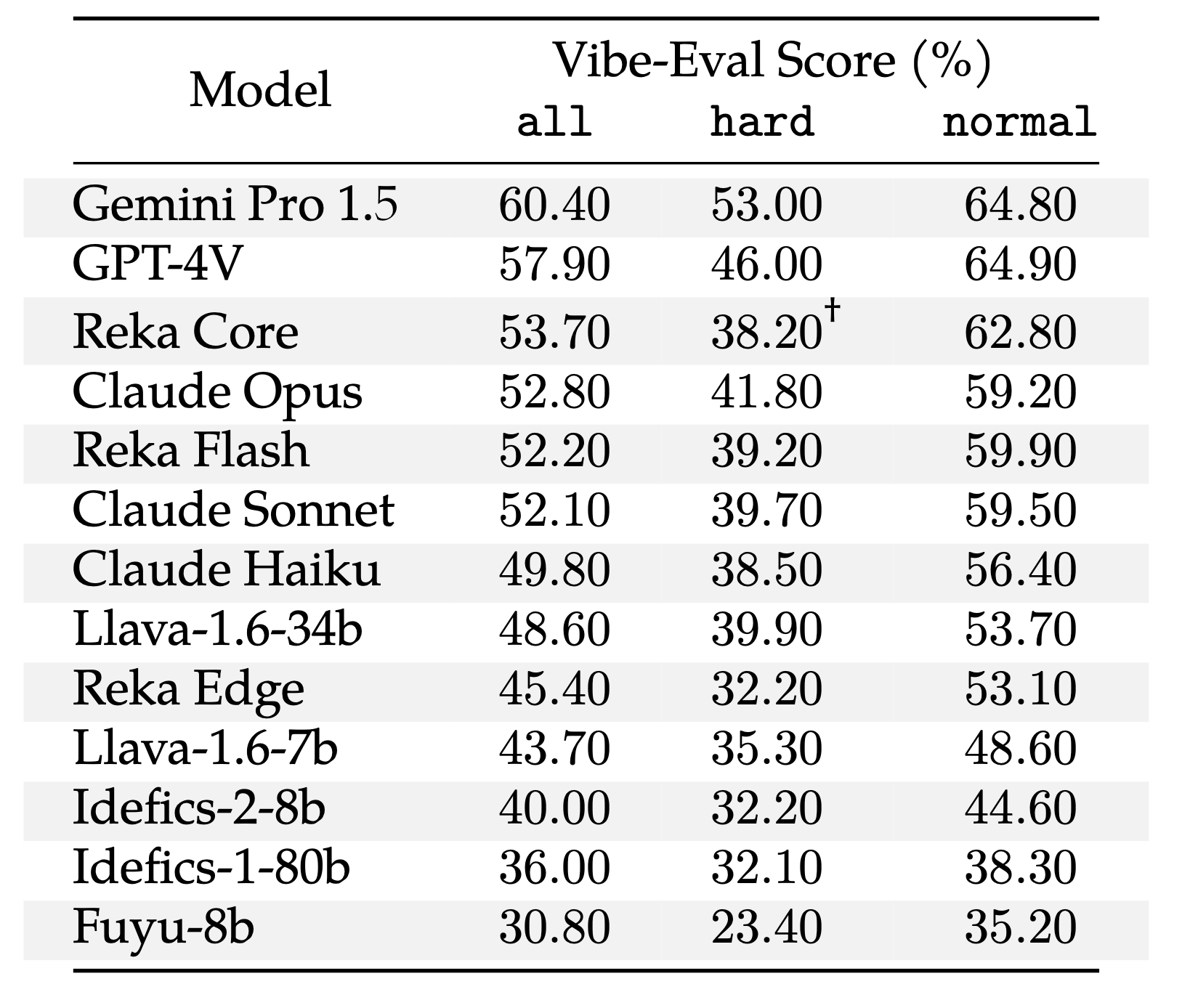

Our overall findings are as follows:
Gemini 1.5 Pro and GPT-4V are pretty much comparable and are clear frontier-class models. They are in a tier above all the other models. Gemini 1.5 Pro is better at hard questions as compared to GPT-4V.
While being a tier lower than Gemini 1.5 Pro and GPT4-V, Reka Core, Flash and Claude-3 Opus are quite close in performance but are still a tier above all the other models. The only anomaly here is the hard set which Core does very poorly which causes Flash to outperform both Claude-3 Opus and Reka Core. This is likely due to the fact that hard set was sourced by referencing the weakness of Reka Core.
Most open source models are generally worse than closed source models. Llava 1.6 34B is relatively decent and did surprisingly well on hard subset but is still generally outperformed by Claude-3 and Reka models.
Human preference ranks maps very well to VibeEval rank, showing that Reka Core evaluator works well to approximate relative performance across models.
Conclusion
At Reka, we strongly believe building solid evaluations move the field forward. Therefore, we’re releasing a high quality benchmark. Our paper includes analysis, insights and discussions about the process of getting to this set of results and recommendations for others to build upon our work. Reka Core is free of charge to use as an evaluator. Please contact us at discord or our contact form for more questions. For obtaining free credits for using Reka Core as an evaluator, please reach out to us!